

Core Concepts
Synopsis
A key concept in the design ideology of Unbase is the earnest belief that State is fundamentally ephemeral. We believe that state may be observed or projected, and only events may be stored or transported. We believe this to be true both metaphorically, and literally from a first-principle-physics standpoint.
This may seem silly at first blush, or perhaps overly philosophical, but this interpretation allows us to reason about data in a way which confers interesting benefits. Chief among them is that when resolving a conflict, we don’t have to reconcile multiple states, which would be a lossy proposition. We may instead reconcile happenings or intentions. With careful optimization, we may also loosely approximate the causal consistency model of the physical universe with reasonable efficiency. The point of this document is to try to explain how that can be done.
Many modern database systems delegate authority to “shards”, each purporting to be the referee and arbiter of state for some subset of the data in the system. These systems seek to create walled gardens of correctness, while conveniently ignoring the consistency model of the overall system; inclusive of services, clients, etc. We argue that a query result-set as provided by a traditional RDBMS is simply a partial replica of the database with a poor consistency model.
In functional programming, it’s very common to employ immutable data structures. These data structures are simple, elegant, and efficient, but seldom used in highly concurrent systems – for reasons we’ll get into below.
Unbase seeks to expand the system model to encompass those nodes formerly considered to be “clients” as first-class participants in storage and computation, limited only by capacity and policy. An Unbase system may accommodate many thousands, or even millions of instances, while offering a first-principle-physics approach to latency reduction at every scale, and strong causal consistency guarantees. See Consistency Model for details.
TL;DR:
Unbase employs a distributed DAG of immutable “Memos”. This structure is similar to a Merkel tree insofar as each event is identified by the unique hash of its precursors and its content. Notwithstanding a ground-up approach to implementation details, as we see it the key novelties of Unbase are twofold:
- Sparse vector clocks, AKA “beacons” (similar in principle to interval tree clocks, but with key differences)
- A probability-based approach to commutative index merging.
Both of which are key optimizations, necessary to offer the Infectious Knowledge consistency model with reasonable efficiency.
Read on for more details.
So, lets start with something easy…
Alice has an immutable data structure
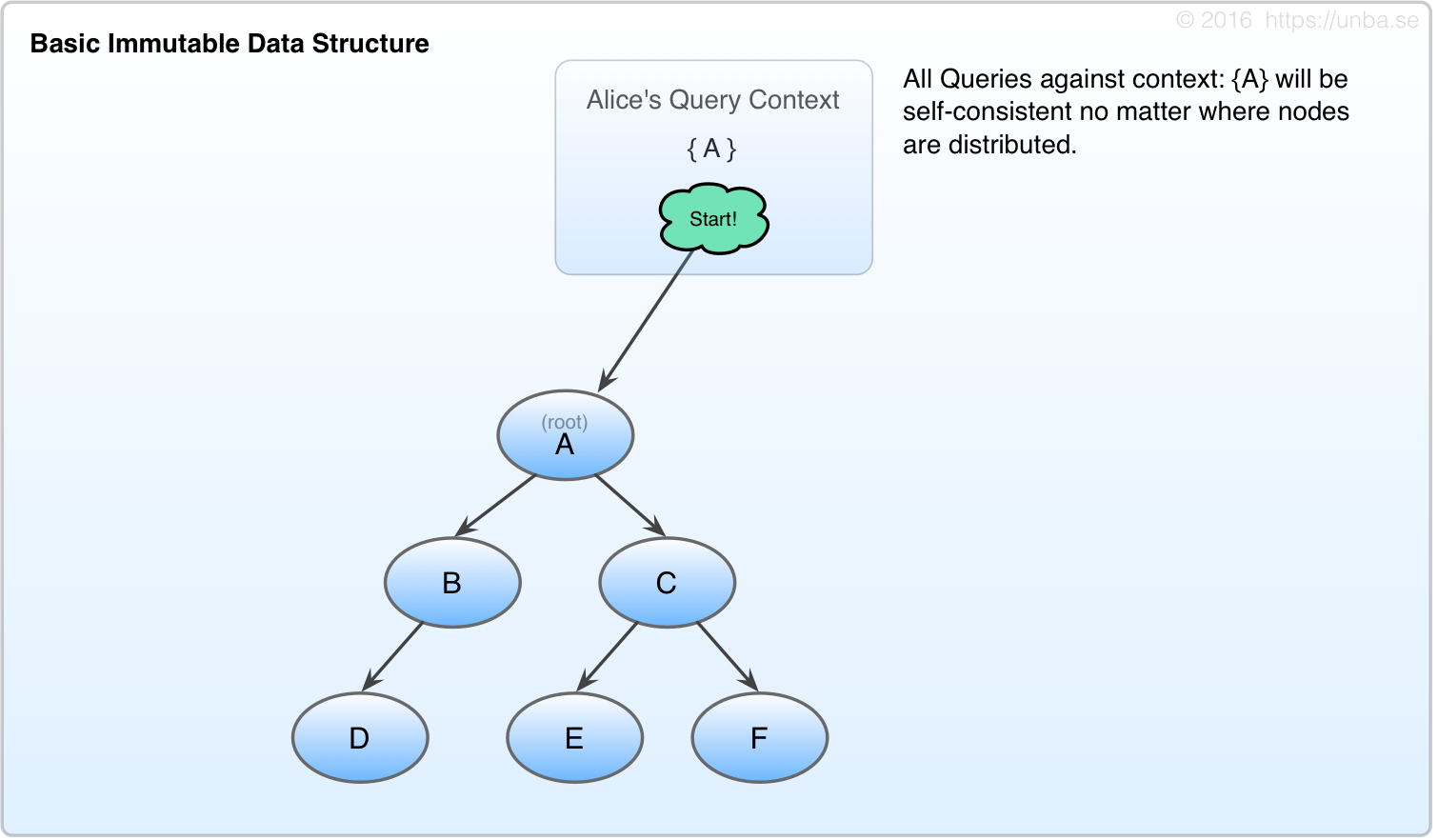
Fig 1. Basic persistent data structure
With immutable data structures, when an given value is “edited” it’s not done by mutation, but rather by originating one or more new nodes, and recreating all parent nodes up to the root node. This provides a compact context against which all subsequent queries will experience a consistent worldview.
Now, Alice decides to make an edit. She keeps her root node in a basket of sorts, which we’re calling the Query Context. By carrying around this Query context Alice can have a consistent view of her data and ensure that no stale data is observed. Once the new nodes are created, she swaps out the old root node for the new one in her Query context:
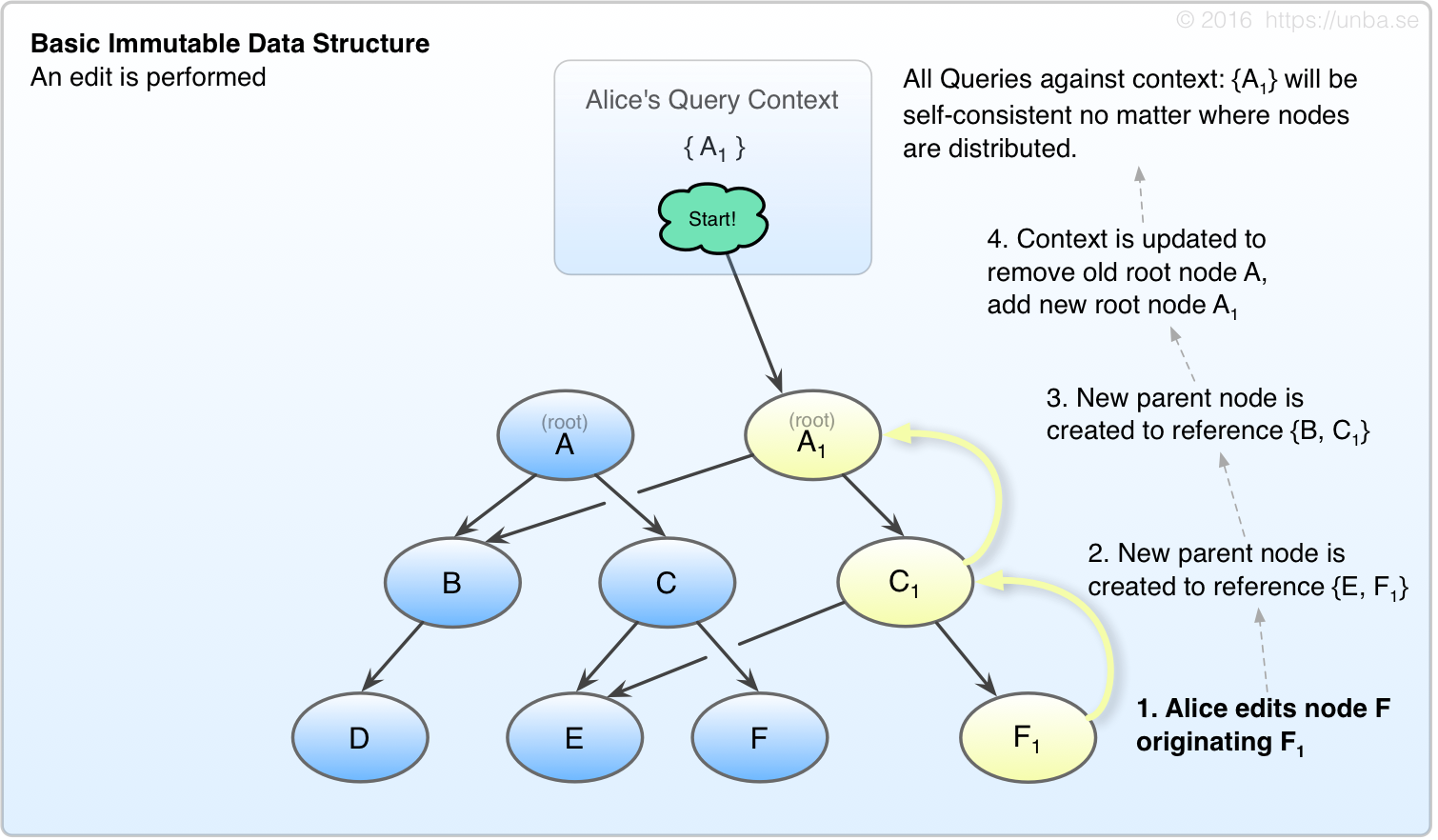
Fig 2. Basic Immutable Edit
Ok, so this is all super straightforward persistent data structures stuff right? But here’s where things start to get interesting:
You might have thought Alice was writing out the whole record for F as F1 but that’s not what’s happening in our case. Instead of writing out the whole record, she emits F1, which is an operation to be applied to, and is causally descendant of F. In Unbase, these are called “Memos”, and everything is made of them.
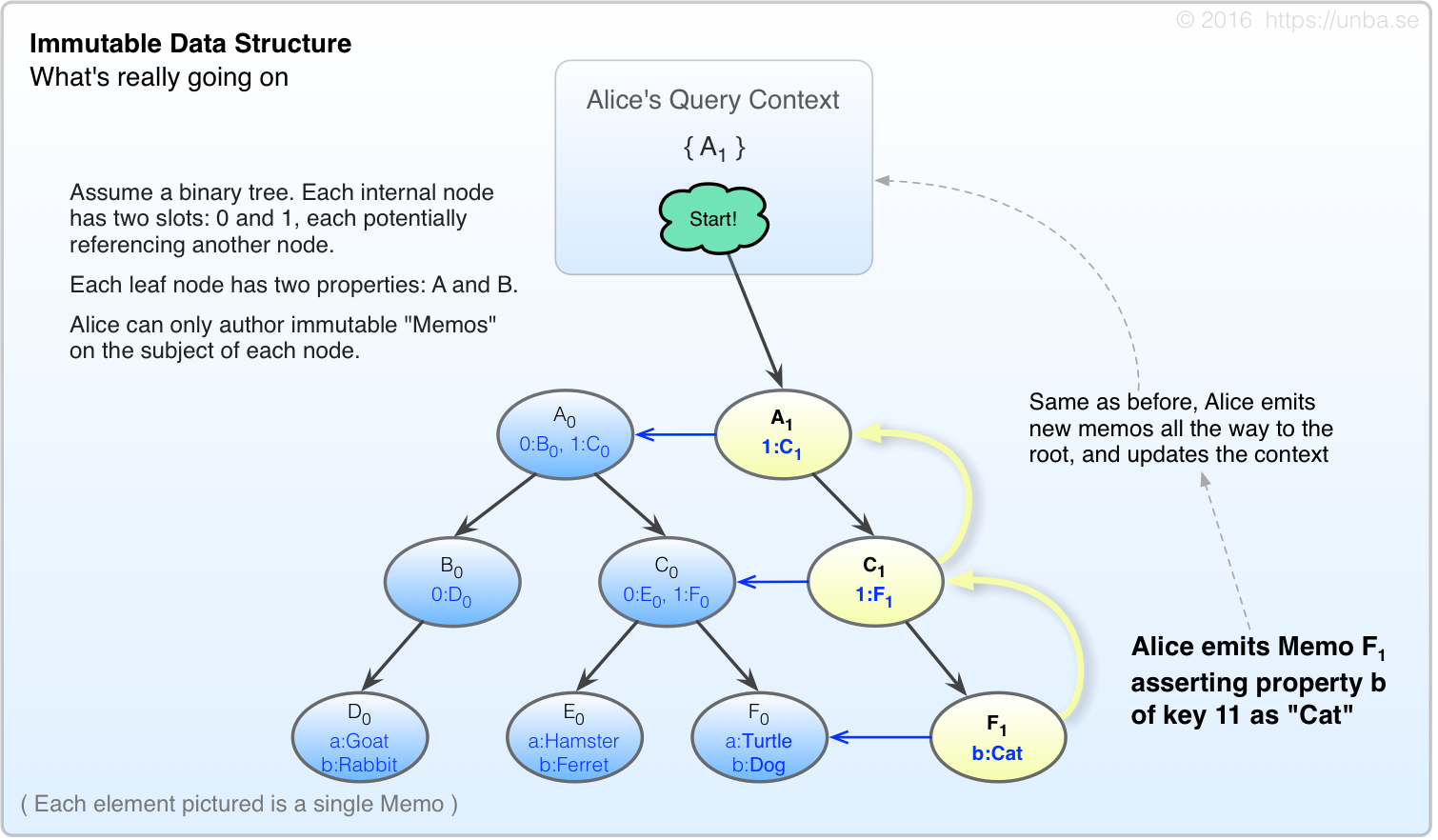
FIG 3. Ok, so we’re emitting immutable Memos, not really editing “Nodes”.
As an exercise, lets ask Alice to perform a query of key 11:
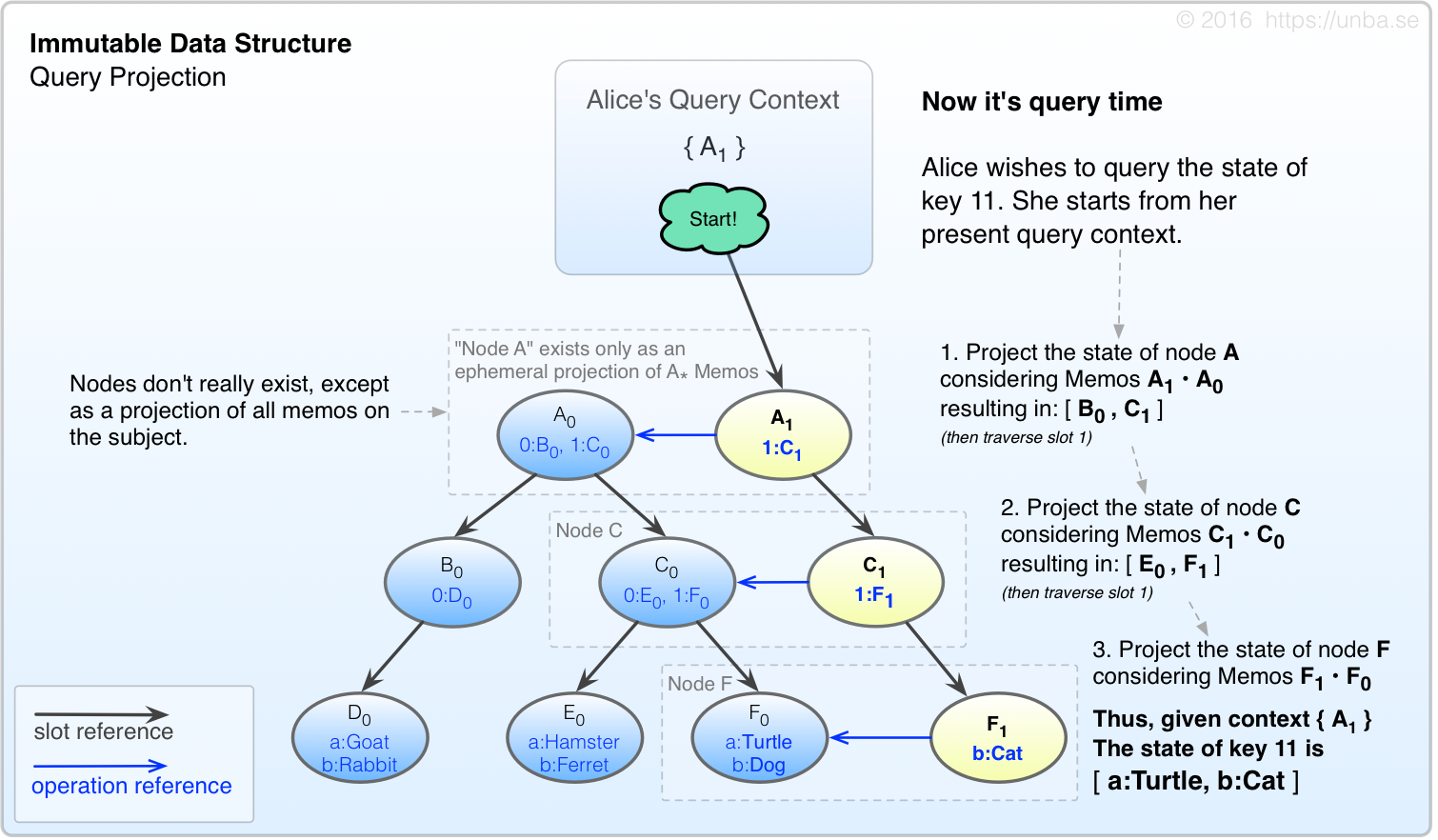
FIG 4. State is merely an ephemeral projection based on a point of view (query context in our case).
Concurrency - Welcome Bob
When others wish to edit key 11, they can go right ahead and emit Memos on the basis of what they know already. We don’t want to wait for coordination. Unbase assumes that all resources are non-exclusive, and conflicts are to be resolved by their datatypes. (Data types and conflict resolution are discussed a bit later)
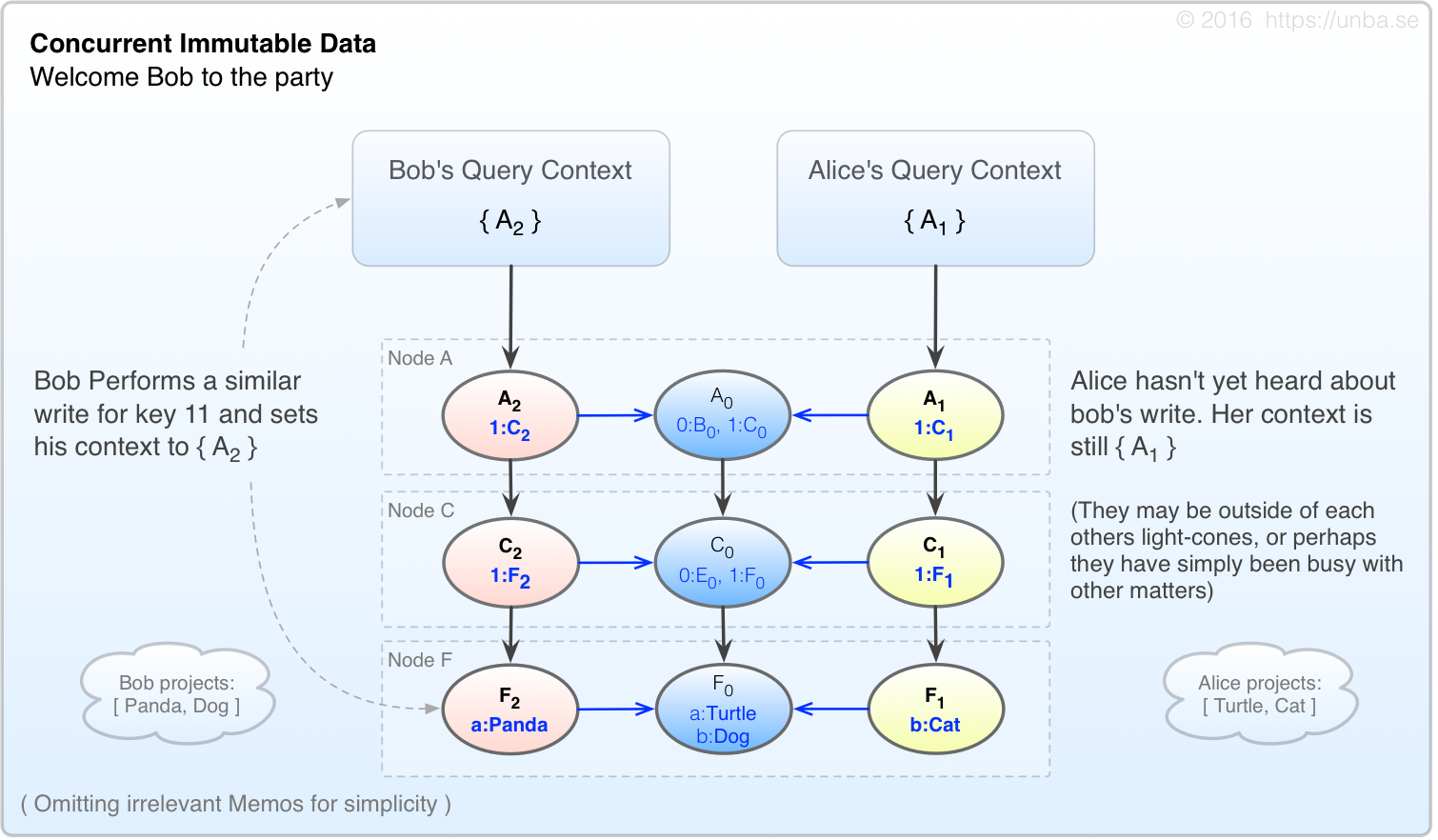
FIG 5. Concurrency is introduced.
When Alice and Bob bump into each other, if they’re interested in having a conversation, they may exchange contexts. When they each try to query the value of key 11 now, they must ensure that each node is projected while considering all memos in their query context. For instance, Alice projects Node A slot 1 as:
A1 • A2 • A0 = 1:[C1, C2, C0]
( slot 0 is omitted for simplicity )
Continuing in this manner, and assuming their contexts are the same, they will each arrive at the same value for key 11.
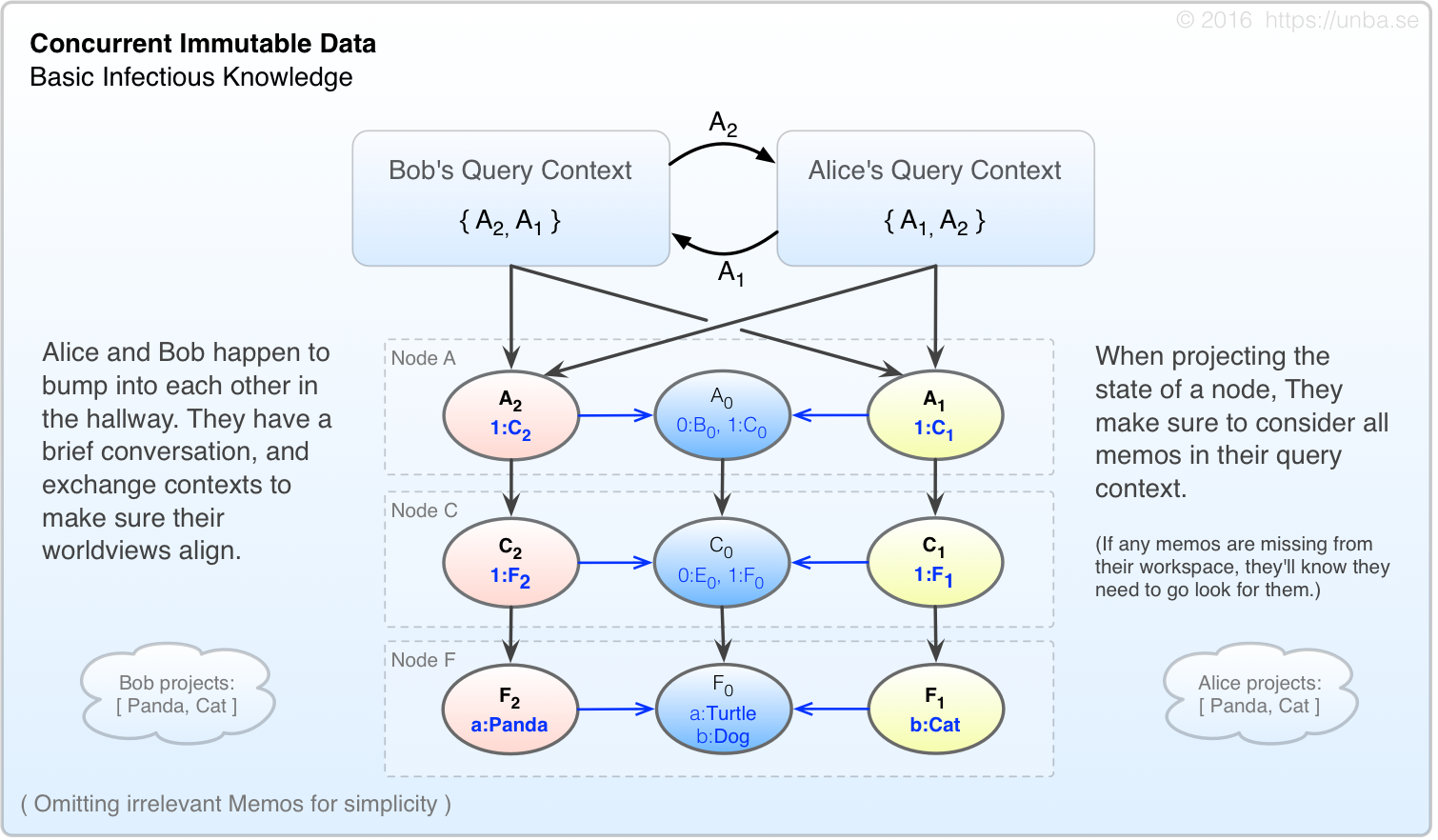
FIG 6. Projection is performed with using all memos referenced by our context.
In the event that Alice had additional memos added to her context by a third party after the discussion with Bob, her projections would at least be mindful of Bob’s context, even if the projected state differed from Bob’s.
Consistency Model
Once context is exchanged, there is no un-ringing that bell – ALL of that party’s subsequent state projections must consider the accumulated context information up to that point. This consistency-model which Unbase implements is referred to as Infectious Knowledge. All agents in the system, including clients, web browsers or otherwise, will be empowered by the Unbase system to exercise this manner of “causal fencing”. The mechanism may be selectively relaxed when desired, but in all cases, the querying party has the option to project a state which is deterministic on the basis of their starting query context.
What’s the point? What have we gained?
Now we have a rudimentary coordination-free system which is capable of providing deterministic state projections for a given query context. A handy benefit of this approach is that the lower-bound latency for state projection of a received context can approach the latency of the sending light-cone itself. This is as good as it gets folks, at least with presently-known physics anyway.
Yes, this lower-bound is a property which we share with many eventual-consistency databases too, except that we also get strong consistency in the bargain. For a given query context, we get to know at query time if our data is stale or not. Sure, we may have to wait under some circumstances, but we will at least know that the data we’re waiting for is probably in our receiving light-cone.
Note on Data Types:
The above scenarios employ a very basic Last-Write-Wins style approach for simplicity of illustration. Unbase seeks to natively support much more advanced data types than can reasonably be pictured here. See Data Types for more details.
OK, so there are a few problems…
Alright, so there’s no free lunch exactly. In setting up the above scenario, we have accumulated a few problems that we have to solve.
Problem #1 - Context Expansion
Inserting few Memos in your query context isn’t so bad, but what about when we’re around for a long time? Or when you invite a few million of your friends to the party? You have a serious context expansion problem.
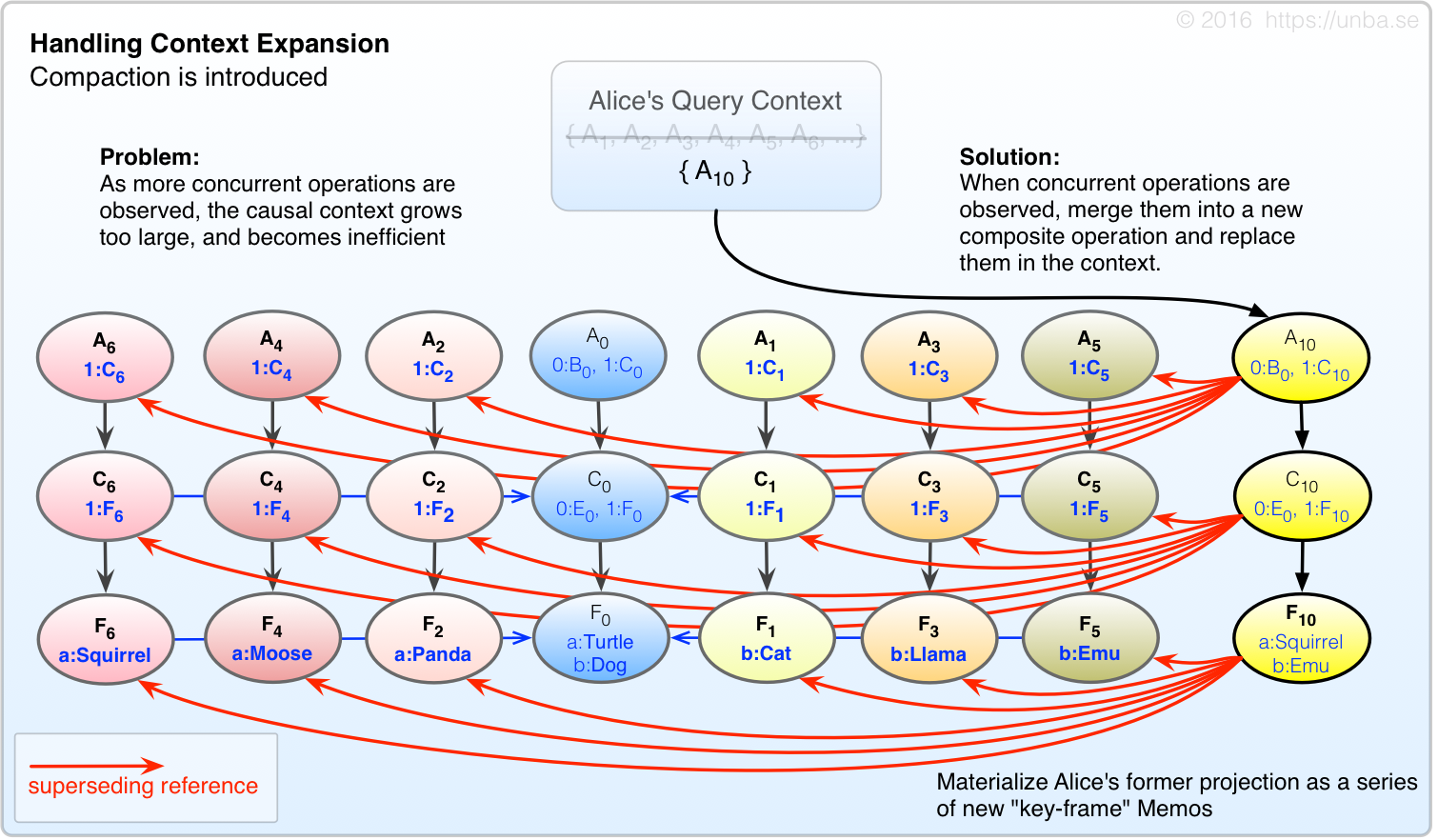
FIG 7. When Query context grows too large, compact it by materializing each node’s projection as a “key-frame” memo, which supersede their predecessor memos.
(TODO: Determine if it’s meaningful for the purposes of this document to differentiate between causal compaction and key-frame creation.)
You might think to yourself “hey, this is the same as state! I want my money back!” There’s a key difference here though – while the key-frame memos are deterministic based on their precursors, and thus an effective optimization, we’re decidedly not assuming that these Memos are the last word in state. If new Memos show up which do not descend the key-frame Memos, then we’ll throw these key-frames away, and re-project them inclusive of all precursors, both old and newly-arrived. That said, it’s possible that a precursor could show up from Alpha Centauri (or a long-offline service) and upset a lot of what we thought was stable history. We aim to give system maintainers a choice of if and how to to assimilate this.
Problem #2 – Write Amplification
Now that we have a mechanism to compress our context, we run smack into another problem: Write amplification. For every payload-bearing memo we originate, we have to originate several more in order to work our way to the root node. Then, when our context grows sufficiently to hit our compaction threshold, there’s several more memos to generate still. With a small number of writers, this isn’t so bad really; but when we’re in system with many writers, the overhead of write amplification could easily overwhelm available bandwidth and computational resources.
So how do we solve this?
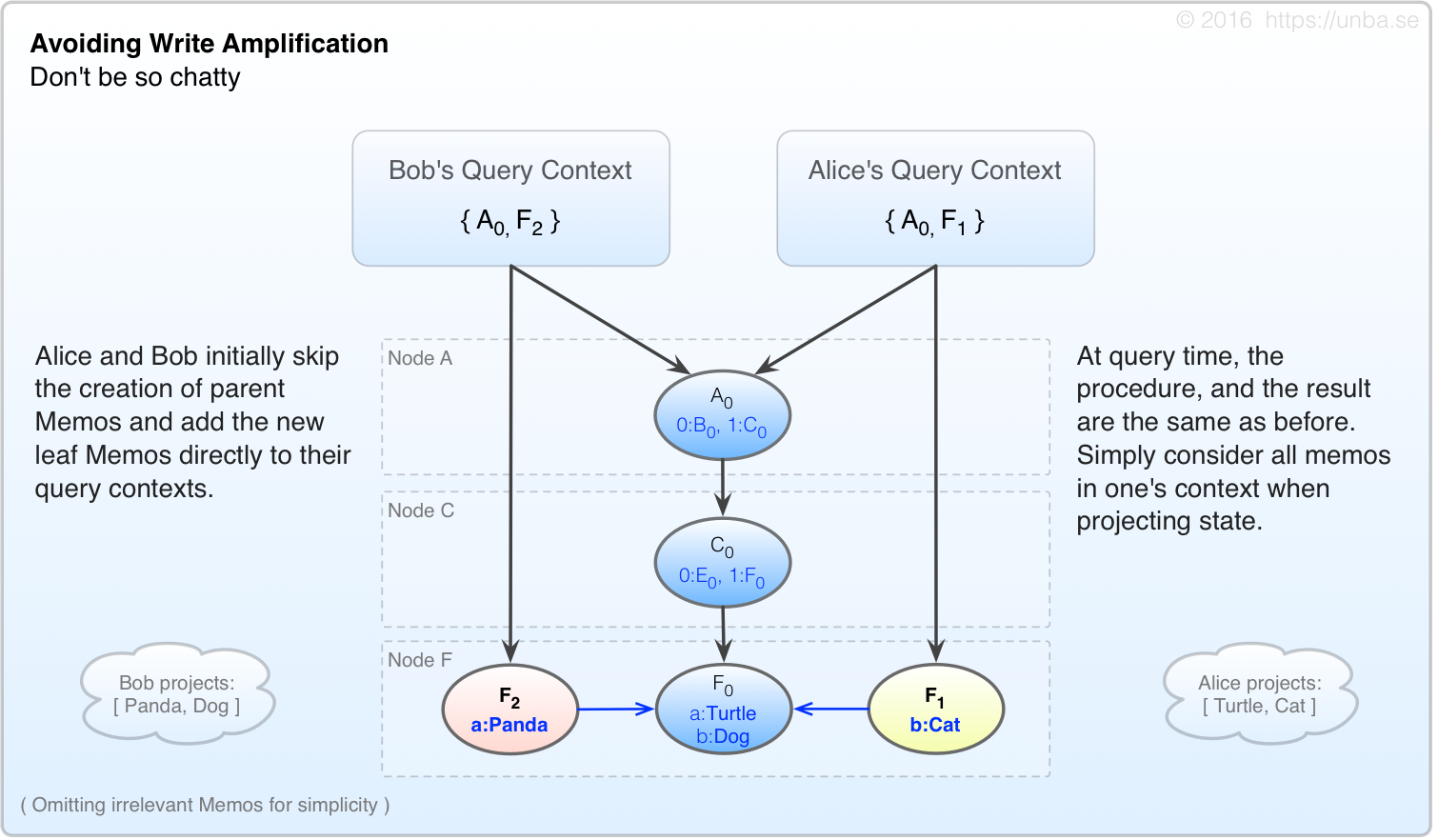
FIG 8. Initially, we skip creation of parent memos, and simply add new leaf memos to the context.
Alice and Bob are now much less chatty per each edit, originating only one Memo each, and adding it directly to their respective query contexts. They create far fewer Memos than before.
Now lets do an exercise again, where Alice and Bob bump into each other and exchange contexts:
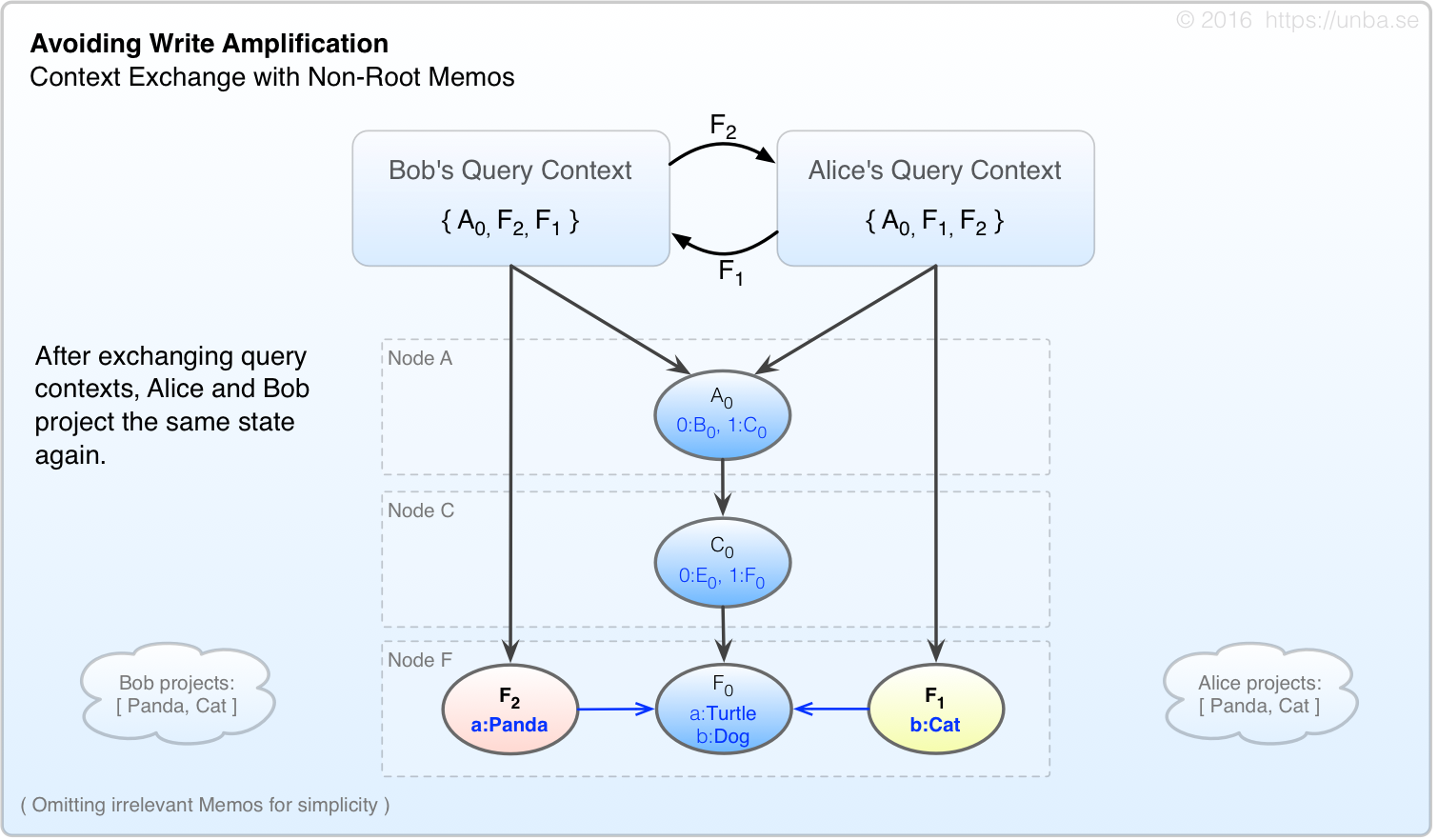
FIG 9. State projection considers all Memos in one’s context.
Just like in Figure 6, Alice and Bob exchange contexts, and arrive at the same deterministic projection on the basis of their (now identical) query contexts. A query context directly contains a relatively small number of specific memos; however it could be considered to logically contain all those Memos which are recursively referenced as well. Whatever Memos are present in one’s query context, either directly, or indirectly (through referential recursion) shall be considered for the state projection of a given node.
But wait!
This just brings us right back to the context expansion problem again! How do we resolve this?
We can use the compaction mechanism discussed above in Figure 7, but instead of doing it immediately, let’s use it only when our context expands past a certain threshold. Moreover, we don’t necessarily have to apply this process all the way to the root node. If a large fraction of the edits are in a certain area of the tree, we can choose to emit only leaf/intermediate consolidating Memos – Essentially applying the same process as in Figure 7, except doing so selectively and incrementally:
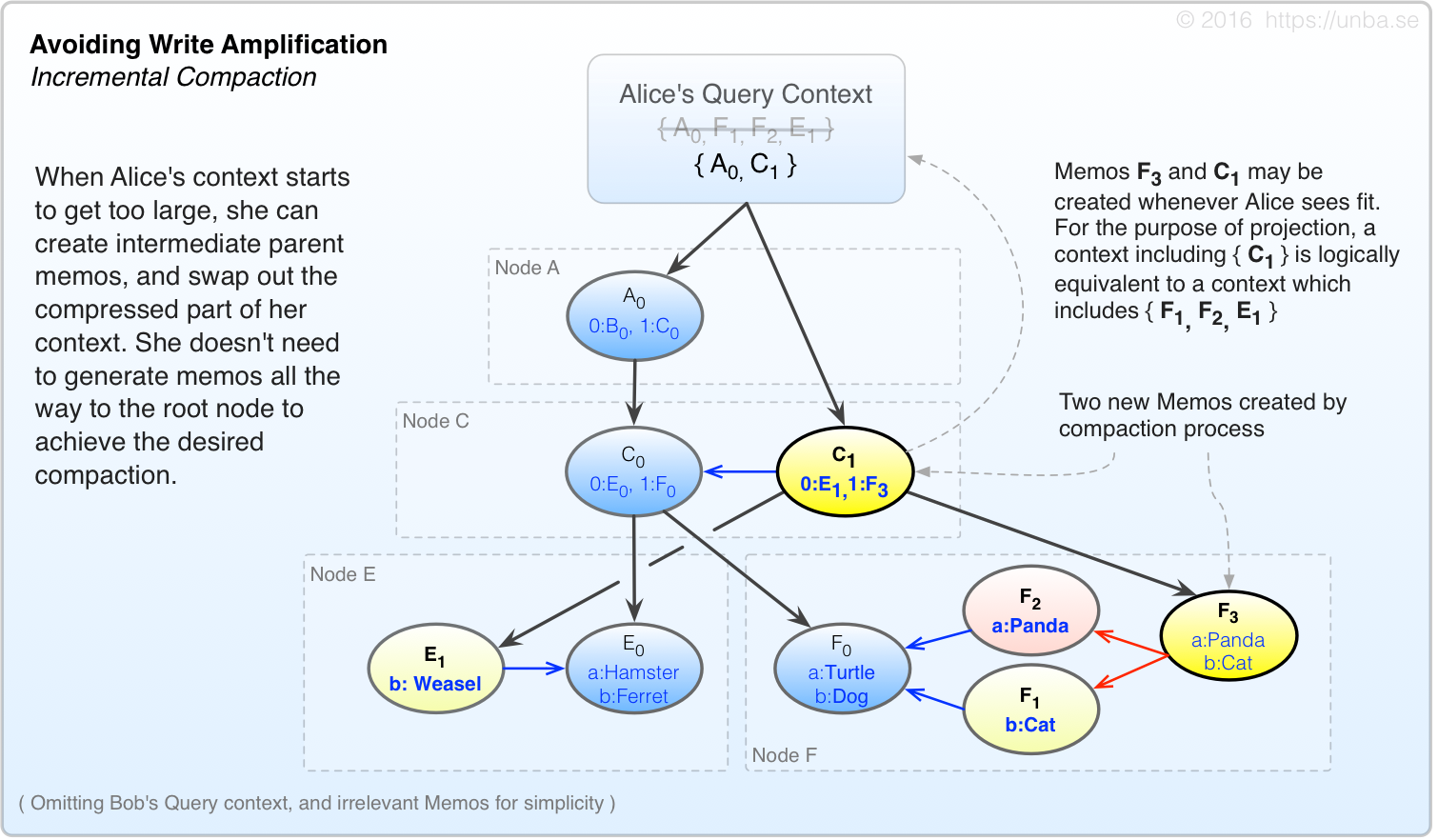
FIG 10. Perform the query context compaction selectively, and incrementally.
In the above scenario, Alice may have made or observed a whole lot of loose-leaf edit Memos on a number of different nodes, perhaps even well beyond those which are pictured. Alice has the option of emitting these intermediate consolidating Memos at any point where she feels like compacting her query context, even in the middle of a transaction – It doesn’t matter (Atomicity and transactions discussed later.)
Challenge #3 – Distributed Merging at-Scale
Alright, we’ve made it this far. Now for the hard part:
How does this behave when it’s not just Alice and Bob at the party – How does it behave when we have a million+ people in the system? It might not be too bad if most of them were reading, with some occasional writes. They’d share contexts among themselves, occasionally resulting in actual context expansion, and occasionally resulting in redundant compaction operations. Because the identity of each Memo is based on the hash of its precursors plus it’s content, only one compaction memo would end up getting stored (even if it was calculated nearly a million times.)
Let’s ask Alice, Bob, and several of their friends to do an exercise. To make things a little more interesting, We’ve decided that Alice and Bob don’t consolidate as early as their neighbors, otherwise the F10 would be received by peers before F9 and our exercise would be a lot less interesting.
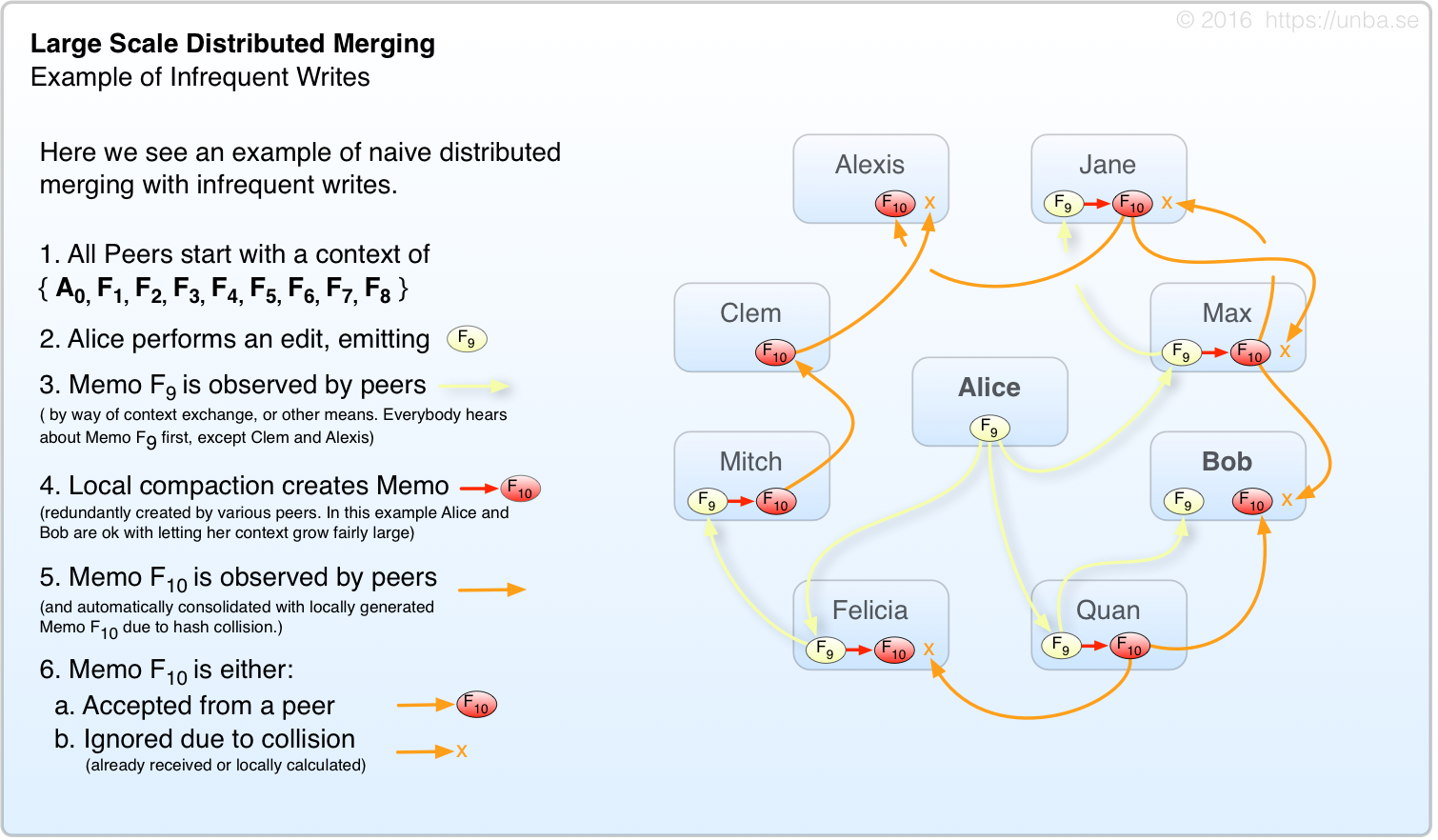
FIG 11. A single writer works ok, but there’s a little too much redundant consolidation.
In the above scenario, we have a rather read-heavy workload with very few writes. It works ok, and the network is quiescent fairly rapidly, but as you can see we have a fair bit of redundant generation/transmission of F10. As in gossip networks, the aggregate upper-bound for write throughput on a given topic is approximately equal to the average individual throughput of each interested party. This is because each write must be propagated to all interested parties. In the case of a system with a well distributed variety of not-so-popular topics, this is somewhat less crucial. In our case, it’s a serious problem. Nearly every party in the system is likely to possess a root index node (indexing discussed a bit later).
Because of these high-interest topics (such as the root index node) and the desire to operate large, and/or write-heavy networks, we must find a way to mitigate this. We must find a way to permit the aggregate write throughput for a given topic to dramatically exceed the average capacity of the interested parties. But how?
Probabilistic Index Merging
Have you ever been to a party where there are 20+ people talking in one room? Chances are, you focused on a few of them, and essentially ignored all the others. Even if you theoretically were within earshot of all of them, you lack the capacity to listen to all of the people at once – It exceeds your input acoustic processing bandwidth. You specifically choose to ignore what most of them are saying. You tune them out so you can use your capacity to understand the people on which you’re focused.
Solving the above problem is quite simple really. When you have more traffic on a given topic than the capacity of each interested party individually, the parties simply ignore the extra chatter which they cannot, or do not wish to process. In our case, rather than tuning into specific groups of people when necessarily, each peer mode decides to a hear a message, or not, on the basis of a carefully calibrated probability calculation.
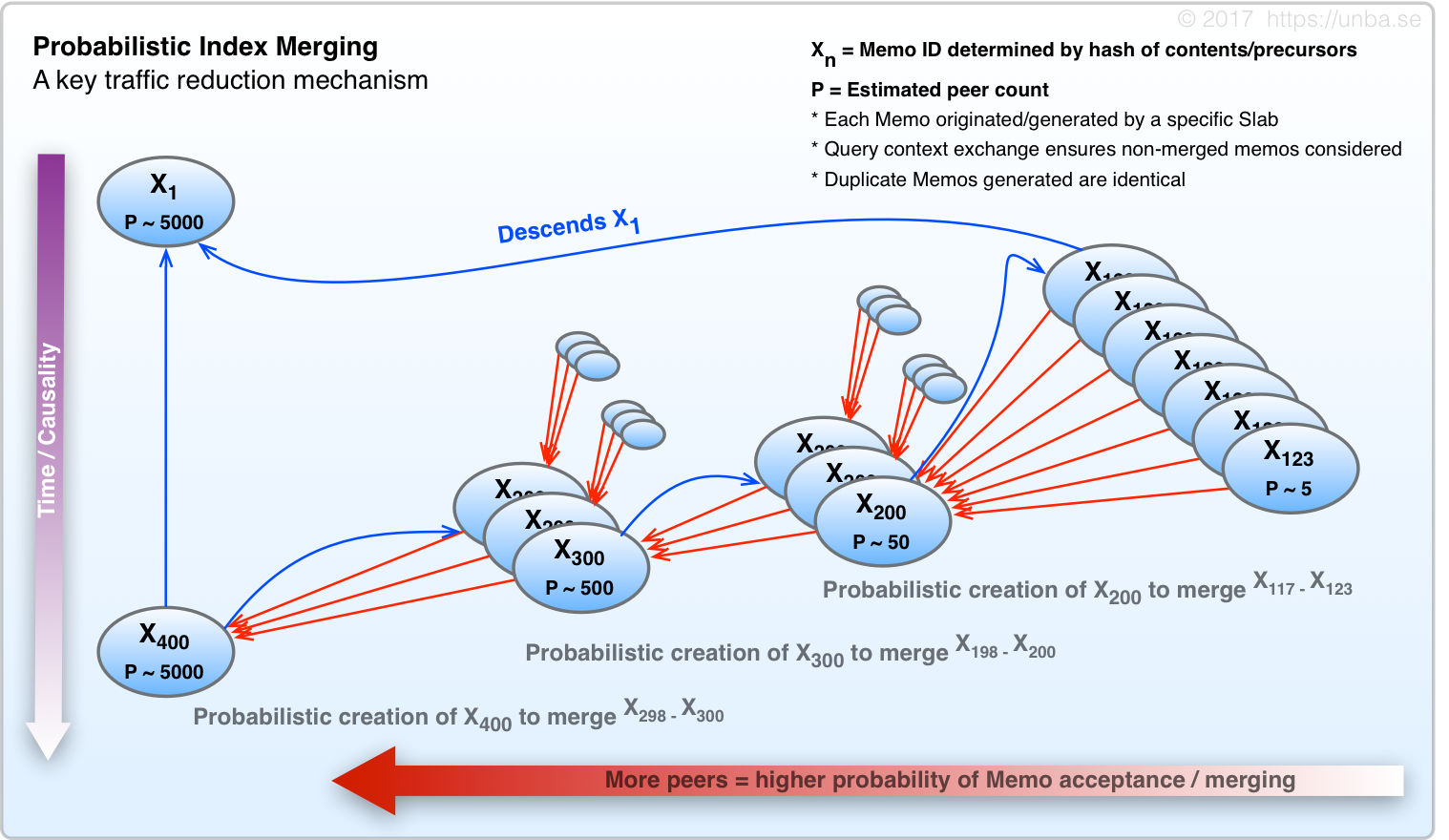
FIG 12.
Probabilistic Beacon Clocks - A key implementation detail
![]()
FIG 13. Beacon Pings reference each other to form a distributed monotonic clock.
Each Slab has one “Beacon” – a monotonically incrementing counter which periodically emits “Ping” Memos bearing the present counter value. The probability of Ping emission by a given Beacon is determined by the relative (inverse of) cardinality of other Beacon pings observed.
The purpose is to create a distributed monotonic clock which is self-tuning to create the smallest amount of logical-timekeeping traffic across the network while still providing acceptable timing references to spatial/network regions.
Commutative Index Merging
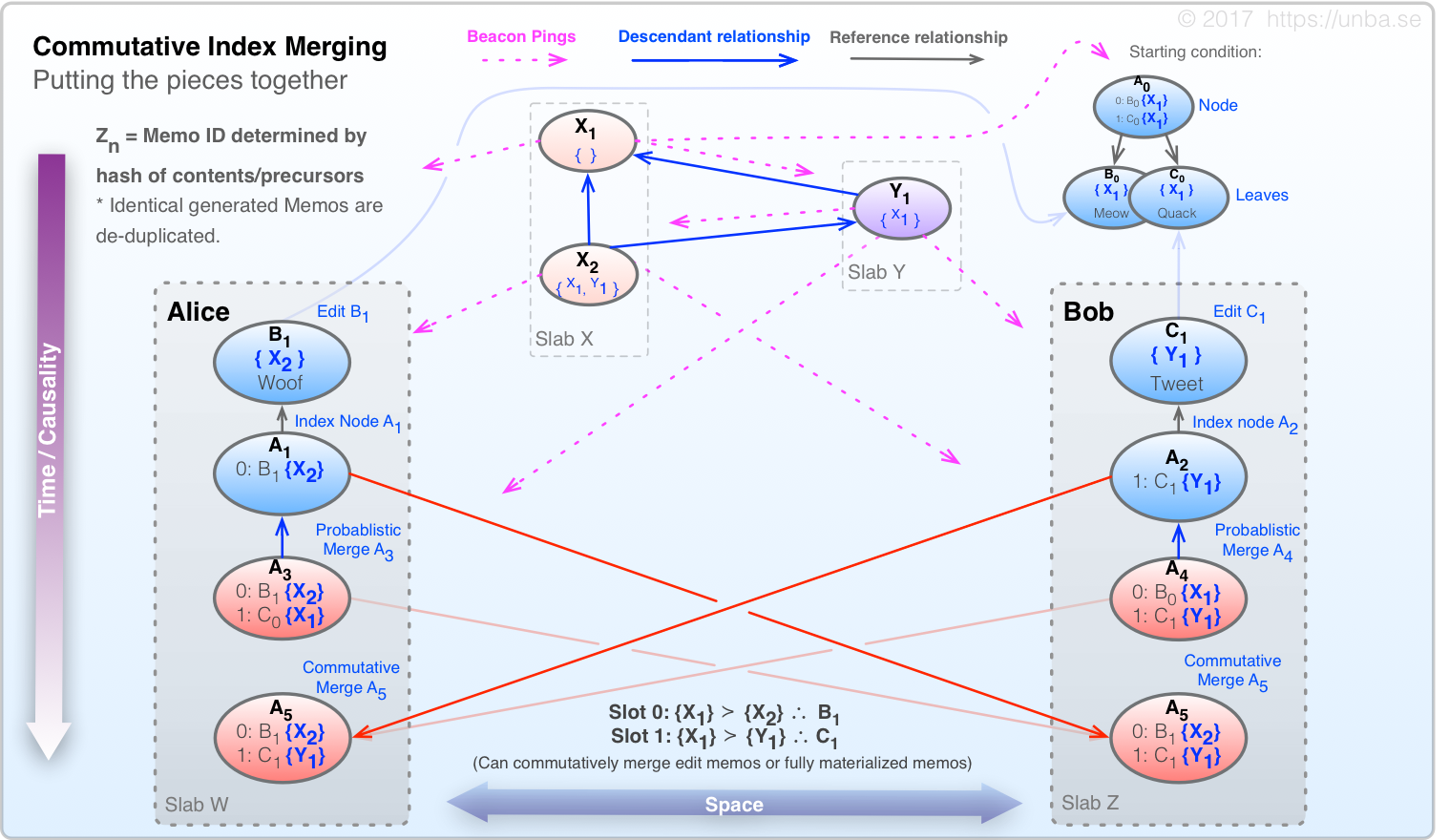
FIG 14.
Gravity and Pressure
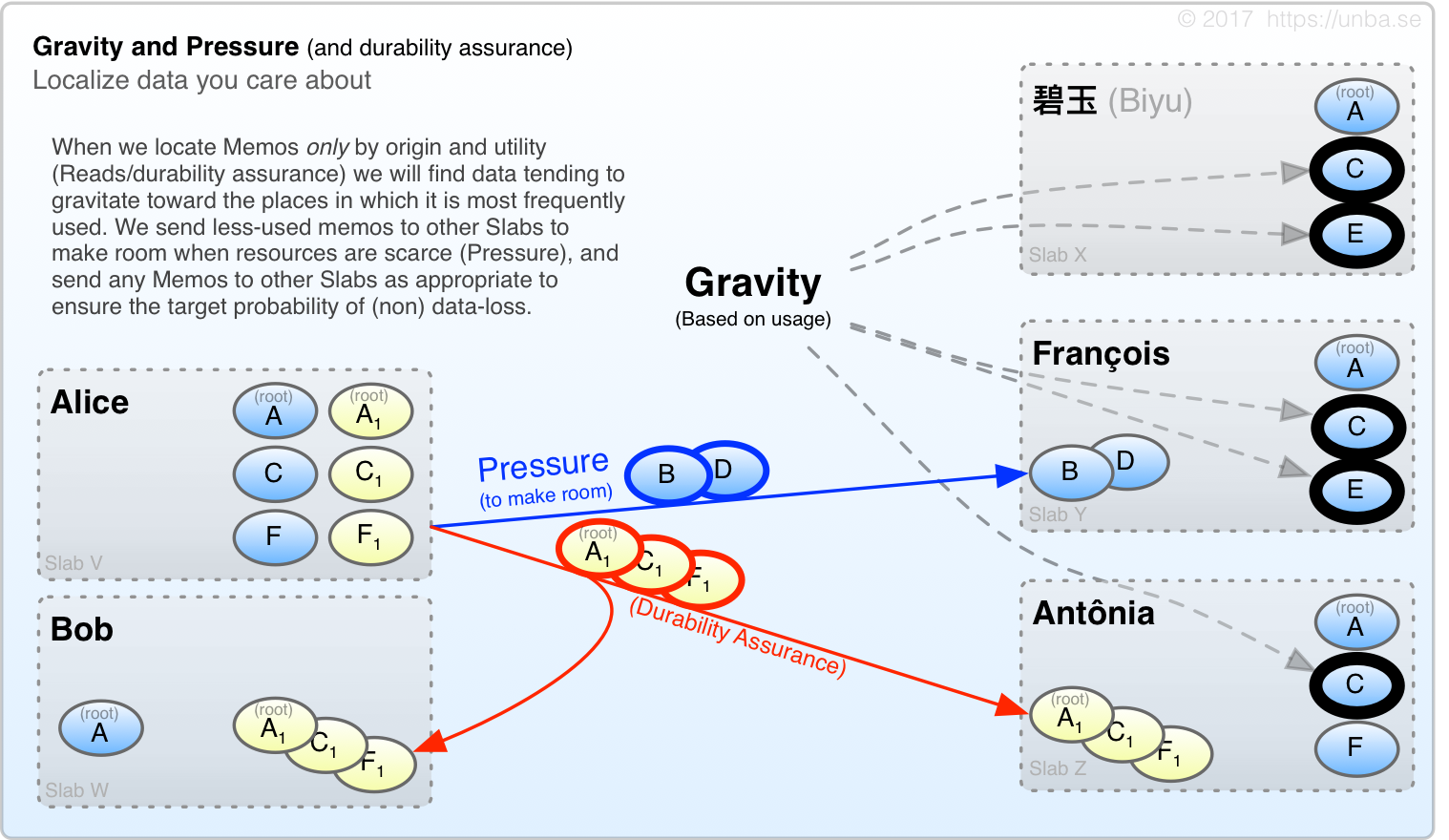
FIG 15.
Notes:
- implementation clarification ( What did we win? )
- Introduce: Model or Entity or Topic ( this is a design goal )
- Why do I need a consistency model for my index.
- To make the system scalable I need to be able to spread my data around without a priori planning ( also a design goal )
- But I also need to be able to find it!
- my data doesn’t actually exist anywhere, by my edits are all over the place!
- probablistic merging and beacon pings